Short-Course and Invited Talks
SC2.6

Chiplet-to-Chiplet Communication Circuits for 2.5D/3D Integration Technologies
Presenter: Kenny C.H. Hsieh, TSMC
More now than ever, conventional single-die package systems are facing both performance and cost challenges with continued CMOS scaling. As such, System-inPackage solutions, where multiple chiplets are integrated by various 2.5D/3D substrate technologies, have become lucrative alternatives. To be economically viable, they require carefully co-optimizing system demand and package technology as well as the interconnects that enable communication between the chiplets. From a system perspective, the interface circuits need to be transparent to minimize power, area, and latency overhead. Here, we will briefly introduce prominent 2.5D/3D package technologies and outline opportunities and challenges presented by these technologies. We will explore circuit design and test considerations for these ultrashort-haul inter-chiplet links, covering topics such as clock schemes and synchronization, low-power design strategies, interconnect routing, and design for testability. We will also discuss recent design examples demonstrating high aggregate data bandwidth at high energy efficiency.
SC3.8

Trends and Design Considerations for Emerging Memories and In-Memory Computing
Presenter: Yih Wang, TSMC
Embedded memory continues to be the key defining component for modern SoC. As applications become more data centric, the performance of SoC for future abundant data computing is increasingly constrained by the bandwidth and energy of accessing data from memory. Alternative memory technologies and computing architectures are been actively explored to address these challenges, including the emerging memory technologies and in-memory computing. In this short course, the present status and key design considerations for various emerging memory technologies will be reviewed. The latest development and challenges for in-memory computing that exploit structural alignment of 2D SRAM or emerging memory arrays for energy-efficient matrix-vector multiplication will be discussed.
FF.3

Heterogeneous Integration Technology Trends at the Edge
Presenter: Chih Hang Tung, TSMC
Edge computing and intelligence has gained momentum recently, made possible partially by novel in-package heterogeneous system integration. An overview on package-level heterogeneous integration platforms are discussed with focus on current products using state-of-the-art technologies. Close proximity at all levels, including chip-to-chip, and horizontal/vertical interconnection density is the underlying enabler for realizing edge device high performance computing using in-package multi-chip system integration technologies. Technology challenges and outlooks with future prospective are discussed as a summary.
JFS3.1

Heterogeneous System-Level Package Integration – Trends and Challenges
Presenter: Frank Lee, TSMC
Heterogeneous package-level integration plays an increasing role in higher functional density and lower power processors for general computing, machine learning and mobile applications. This paper will review technology trends and challenges for 2.5D and 3D package-level integration with special focus on system-technology co-optimization of the die partitioning, electrical interfaces, power delivery, thermal modeling and EDA flows.
Symposium on VLSI Technology
TC1.1

Enabling Multiple-Vt Device Scaling for CMOS Technology beyond 7nm Node
Presenter: Vincent Chang, TSMC
For the first time, multiple-Vt (multi-Vt) device options with Vt range > 250 mV are achieved in standard cells at dimensions beyond 7nm technology node. To overcome the common scaling challenges of potential device options such as FinFET and gate all-around (GAA) nanosheet transistor – gate length and cell height scaling, key enablers are identified, including novel, thin, and conformal work function metal (WFM) with enhanced patterning efficiency, high-k (HK) engineering, and precise WFM patterning boundary control. This work enables design flexibility for advanced CMOS technology beyond 7nm node with critical differentiators.
TC1.3

Cold CMOS as a Power-Performance-Reliability Booster for Advanced FinFETs
Presenter: H. L. Chiang, TSMC
We present advanced FinFET characterization and circuit analysis at reduced temperatures down to 77 K. Steepened subthreshold slope enables threshold voltage (VTH) and supply voltage (VDD) scaling for ~0.27x power reduction without sacrificing logic switching speed. With simultaneous VTH scaling, SRAM can operate at the same low VDD 0.4V. Improved gate dielectric reliability raises maximum VDD for >70% speed boost when single thread performance is needed. Taking advantage of lower Cu wire resistance at 77 K, the repeaters for global signal propagation can be redesigned for 80% energy reduction. Increased thermal conductivity of silicon at low temperature reduces self-heating and further improves power efficiency. When refrigeration power is included, net power reduction can be achieved when cooling efficiency exceeds ~ 50% of Carnot limit. We present effective VTH reduction methods for both nFET and pFET, critical for attaining high performance for cold CMOS.
TH1.1

Low Temperature SoIC Bonding and Stacking Technology for 12/16-Hi High Bandwidth Memory (HBM)
Presenter: C. H. Tsai, TSMC
A 12-high (12-Hi) die stack using low temperature SoIC bonding and stacking technology is presented and demonstrated for the application of HBM. The daisy chains in the 12-Hi structure incorporating over ten thousand TSVs and bonds are tested. Liner I-V curves are obtained to demonstrate the good bonding and stacking quality. The electrical link from a base logic die to top DRAM is built up to study the bandwidth and power consumption. Compared to μbump technology, the bandwidth for 12-Hi and 16-Hi structures using the SoIC technology shows the improvement of 18% and 20%, respectively and the power efficiency demonstrates the improvement of 8% and 15%, respectively. Also, the thermal performance for the 12-Hi and 16-Hi SoIC-bond structures are improved by 7% and 8%, respectively. Based on the proposed technology, the scalability of bond pitch to sub-ten μm and die thickness to be thinner is prospected.
TH1.5

Immersion in Memory Compute (ImMC) Technology
Presenter: C. T. Wang, TSMC
Immersion in Memory Compute (ImMC) technology with multiple chips and functions in multi-layer stacking integrated using System on Integrated Chips (SoIC™) technology is presented. The technology provides multiple compute and memory chips to interconnect each other to gain computing power and memory bandwidth. The interconnect parasitics, bandwidth density and power efficiency are analyzed using N7 light IO transceiver. The ImMC compared with 3DIC with bridge and with shared die, respectively, using bump and TSV, is studied. The ImMC is 16x, 14x, and 224x better than the 3DIC with bridge in bump density, data rate, and bandwidth density. The transceiver power and size for the ImMC is only 1% of those for the 3DIC.
TM1.2

An Approach to Embedding Traditional Non-Volatile Memories into a Deep Sub-Micron CMOS
Presenter: Chia-Sheng Lin, TSMC
This work presents an example of 16nm FinFET CMOS with an embedded flash 40nm memory employing Wafer-on-Wafer (WoW) technology. Our results show comparable embedded flash performance, CMOS logic speed and power consumption comparing corresponding circuits before and after the 3D assembly. WoW integration can provide embedded flash solution for advanced CMOS nodes where no solutions currently exist. The method is also applicable for embedding other functionalities into the advanced CMOS.
TM2.3

Industrially Applicable Read Disturb Model and Performance on Mega-Bit 28nm Embedded RRAM
Presenter: Chang-Feng Yang, TSMC
The read disturb performance and industrially applicable model of mega-bit level embedded RRAM with standard 28 nm select transistor are demonstrated in this study. At first, 100k endurance test on 0.5 Mb RRAM 1T1R array is implemented and non-degraded memory window with high read disturb immunity results are acquired. Contrary to conventional analysis on major bits, the read disturb model is especially investigated on tail bits in this work. Furthermore, the read disturb performance for chip user condition with nano-second level pulse width is well emulated by long pulse, which provides a time-efficient way to evaluate read disturb performance at product level. As a consequence, the mega-bit 28 nm RRAM array in this work is able to sustain larger than 1E18 read counts at a rigorous fail criteria.
TM3.2

Reliability Demonstration of Reflow Qualified 22nm STT-MRAM for Embedded Memory Applications
Presenter: Chia-Yu Wang, TSMC
We demonstrate the reliability of reflow qualified embedded STT-MRAM integrated on 22nm. STT-MRAM is capable of 1E5 endurance cycles across temperature (40/25/125°C) with extremely low BER (mean 0.04 ppm, -40°C) and can pass 1M cycles by an enhanced process. BERs post three cycles of 260°C solder reflow are below 1 ppm for AP/P states. Due to high energy barrier for flipping states, chips can meet the retention lifetime spec (>200°C at 10yrs, BER 1 ppm) with a large margin. The balance of retention between AP and P can be adjusted in an optimized process. In addition, we investigate the impact of magnetic field applied at tilted angles and report standby immunity can reach 600 Oe at 125°C for 10 years for fields tilted 60 degrees from parallel to the die surface. Magnetic shields are demonstrated to sustain data exposed to perpendicular fields up to 3.5k Oe at 25°C, 100 hours.
TN1.7
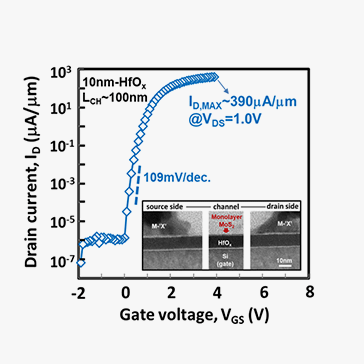
High On-Current 2D nFET of 390μA/μm at VDS = 1V using Monolayer CVD MoS2 without Intentional Doping
Presenter: Ang Sheng Chou , TSMC
We demonstrate the highest nFET current of 390 μA/μm at VDS = 1 V based on CVD MoS2 monolayers without intentional doping. The transistor exhibits good subthreshold swing of 109 mV/decade, large ION/IOFF ratio of 4 x 108, and nearly zero DIBL. The high on-current achieved in monolayer MoS2 nFET is mainly attributed to the thin EOT ~2 nm of HfOx gate oxide, short gate length of 100 nm, and low contact resistance ~1.1 kΩ-μm.
Symposium on VLSI Circuits
CF1.1

Embedded PLL Phase Noise Measurement Based on a PFD/CP MASH 1-1-1 ΔƩ Time-to-Digital Converter in 7nm CMOS
Presenter: Mao-Hsuan Chou, TSMC
We propose an embedded PLL phase noise measurement macro for cost-effective SoC test based on a phase-frequency detector/charge pump (PFD/CP) MASH 1-11 ΔƩ time-to- digital converter (TDC). The decimated TDC output stream is post-processed to extract the phase jitter and noise spectrum. Measuring low jitter requires a short and precise reference delay which we generate with a charge-based pseudo-DLL that locks to the reference delay itself. Using a 14GHz LC-PLL built in 7nm CMOS as a demonstration vehicle, this macro measures 2.80ps rms jitter which closely matches 2.89ps measured by a phase noise analyzer. The built-in self-test (BIST) macro consumes 12.2mW on a 1.2V supply, occupying only 0.066mm2 which is only one-third of the PLL area.
CM2.4

A 22nm 96Kx144 RRAM Macro with a Self-Tracking Reference and a Low Ripple Charge Pump to Achieve a Configurable Read Window and a Wide Operating Voltage Range
Presenter: George Tsou, TSMC
An RRAM macro equips a hybrid self-tracking reference and a low ripple charge pump is presented to realize the configurable read windows and a consistent write performance over operation voltage range 1.62V~3.63V. It shows 6.5ns and 10ns of access time at 0.7V can be achieved for OTP (one-time-program) and 10K endurance applications, respectively.
CW1.3

A 4-to-18GHz Active Poly Phase Filter Quadrature Clock Generator with Phase Error Correction in 5nm CMOS
Presenter: James Chen, TSMC
We present a high-accuracy wideband quadrature clock generator (QCG) built in 5nm finFET CMOS. To achieve low power and high bandwidth, we employ an active poly phase filter (APPF) to generate the quadrature phases with 6dB gain boost and 30% bandwidth extension. The subsequent quadrature error corrector (QEC) and phase error detector (PED) corrects the APPF output phases with phase interpolation to achieve <1° quadrature error across 4–18GHz. At 18GHz, jitter integrated across 100kHz–1GHz and 100kHz–9GHz is respectively 148 and 218fs with 154fsrms phase jitter measured at 14GHz. The noise floor is below –138dBc/Hz at 1GHz offset. The QCG occupies 0.0017mm2 and consumes only 21mW on a 1.0V supply to yield a FoM of 1.16mW/GHz.
JFS5.5

Heterogeneous Power Delivery for 7nm High-Performance Chiplet-Based Processors Using Integrated Passive Device and InPackage Voltage Regulator
Presenter: Alan Roth, TSMC
We demonstrate two heterogeneous solutions to improve power delivery to High-Performance Computing (HPC) processors. The scalable HPC vehicle integrates two 7nm CMOS processor chiplets, each with four ARM® Cortex®-A72 cores, that are mounted on a Chip-on-Wafer-on-Substrate (CoWoS®) silicon interposer [1]. In the first solution, Integrated Passive Device (IPD) capacitors are placed directly beneath the interposer to provide more accessible and effective supply noise decoupling. The result is 3.9% higher maximum clock frequency at a core supply of 1.135V. In the second solution, the processor is powered by a laterally mounted in-Package Voltage Regulator (PVR) built in 28nm CMOS augmented with high-permeability on-die inductors. The processor performance provided by the buck converter-based PVR matches that by an off-package External Voltage Regulator (EVR). As processor power increases with higher core counts, PVRs with on-die inductors will be increasingly compelling for efficient system power delivery.